
If you have ever opened a Theory of Computation textbook and felt your brain short circuit at the words “deterministic” and “non-deterministic,” you are not alone. DFA and NFA confuse almost every student in their first week of automata theory, and the confusion usually comes from one thing: nobody explains why these two machines exist in the first place.
This guide breaks down both concepts from the ground up, with plain language explanations, real diagrams in words, a step-by-step conversion walkthrough, and a revision section built for exams and interviews.
What Is a Finite Automaton?
A finite automaton is a simple computing model used to recognize patterns in strings of symbols. It reads input one symbol at a time and moves between a limited number of “states” based on what it reads. At the end of the input, it either lands in an accepting state (the string is valid) or it doesn’t (the string is rejected).
Think of it as a machine with a memory so small it can only remember which state it is currently in, nothing more.
Components of a Finite Automaton
Every finite automaton, whether DFA or NFA, is built from five parts:
- States (Q): the finite set of conditions the machine can be in
- Alphabet (Σ): the set of symbols the machine can read
- Transition function (δ): the rule that decides which state to move to next
- Start state (q0): where the machine begins
- Accepting states (F): the states that mean “this string is accepted”
Why Finite Automata Matter in Computer Science
Finite automata are not just a theoretical exercise. They form the backbone of:
- Compilers, which use them to scan and tokenize source code
- Search engines and text editors, which use them for pattern matching
- Network protocols, which use them to validate packet sequences
- Digital circuit design, where states map to hardware logic
Understanding DFA and NFA is really understanding how machines “think” in steps, which is the foundation for everything from regex engines to programming language compilers.
What Is DFA (Deterministic Finite Automata)?
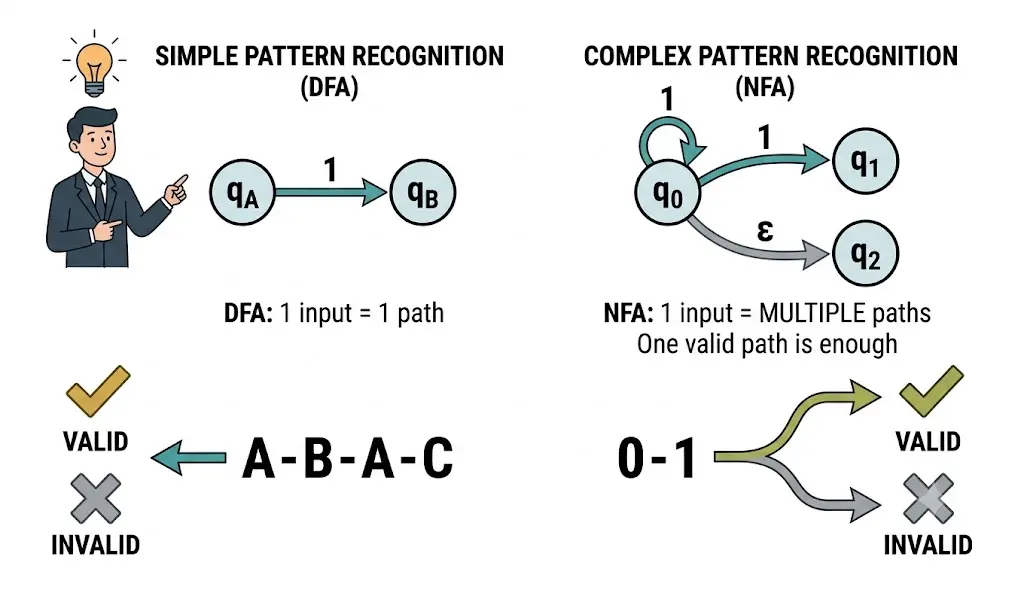
A DFA is a finite automaton where, for every state and every input symbol, there is exactly one defined next state. No guessing, no branching, no ambiguity.
Formal Definition
A DFA is formally written as a 5-tuple: (Q, Σ, δ, q0, F)
Here, the transition function δ is defined as:
δ: Q × Σ → Q
This means for any given state and any given input symbol, the function returns exactly one state. There is no room for multiple outcomes.
DFA Characteristics
- Exactly one transition per input symbol per state
- No epsilon (empty string) transitions allowed
- Every input symbol must have a defined transition from every state
- The machine follows a single, predictable path through the states
- Easier to implement directly in hardware or software
DFA State Transition Diagram
Picture a circle labeled q0 (the start state, shown with an arrow pointing into it). From q0, an arrow labeled “0” loops back to q0, and an arrow labeled “1” goes to q1. From q1, an arrow labeled “1” loops back to q1, and an arrow labeled “0” goes back to q0. State q1 has a double circle, marking it as the accepting state.
This simple diagram represents a DFA that accepts any binary string ending in “1.”
DFA Example
Problem: Design a DFA that accepts all binary strings ending in “1.”
- States: q0, q1
- Start state: q0
- Accepting state: q1
- On input 0: q0 → q0, q1 → q0
- On input 1: q0 → q1, q1 → q1
Trace the string “101”: start at q0, read 1 (move to q1), read 0 (move to q0), read 1 (move to q1). The machine ends at q1, which is accepting, so “101” is accepted.
Real-World Applications of DFA
- Lexical analyzers in compilers, which scan source code character by character
- Vending machines and traffic light controllers, where every state has one clear next step
- Spell checkers and basic string matching tools
- Protocol state machines in networking hardware
What Is NFA (Non-Deterministic Finite Automata)?
An NFA is a finite automaton where a state can have zero, one, or multiple transitions for the same input symbol. It can also include epsilon transitions, which allow the machine to change states without consuming any input at all.
Formal Definition
An NFA is also written as a 5-tuple: (Q, Σ, δ, q0, F)
But here, the transition function is defined differently:
δ: Q × (Σ ∪ {ε}) → P(Q)
P(Q) means the power set of Q, so the result of a transition is a set of possible next states, not a single one.
NFA Characteristics
- A state can have multiple transitions for the same symbol
- Epsilon transitions are allowed, letting the machine move states without reading input
- A state can have zero transitions for a given symbol (no defined path)
- The machine is considered to accept a string if at least one possible path leads to an accepting state
- Often simpler to design for complex patterns, even though it looks more chaotic
NFA State Transition Diagram
Picture two states, q0 and q1, both circles, with q0 as the start state and q1 as the accepting state (double circle). From q0, on input “1,” there are two arrows: one looping back to q0 and one going to q1. This is the key visual difference from a DFA: one state, one input symbol, two possible destinations.
NFA Example
Problem: Design an NFA that accepts binary strings ending in “1.”
- States: q0, q1
- Start state: q0
- Accepting state: q1
- On input 0: q0 → q0
- On input 1: q0 → q0 and q0 → q1 (two possible paths)
Trace the string “01”: start at q0, read 0 (stay at q0), read 1 (branch into two possible states, q0 and q1). Since one of the resulting states, q1, is accepting, the string “01” is accepted.
Real-World Applications of NFA
- Designing regular expression engines, since regex patterns map naturally to NFA structure
- Early-stage pattern matching algorithms before conversion to a faster DFA
- Modeling problems where the design itself is more intuitive with branching choices
- Theoretical proofs and language equivalence work in computer science research
Difference Between DFA and NFA
The core difference: a DFA has exactly one transition per state per input symbol, making it fully predictable, while an NFA can have multiple transitions (or none) per state per input symbol, and may also include epsilon transitions, making it explore several possibilities before deciding whether to accept a string.
Key Differences at a Glance
- Transition behavior: DFA has single, fixed transitions; NFA can have multiple or zero transitions
- Determinism: DFA’s next state is always certain; NFA’s next state may branch
- Epsilon transitions: Not allowed in DFA; allowed in NFA
- Implementation: DFA maps directly to code or hardware; NFA usually needs simulation or conversion first
- State complexity: DFA can require more states for the same language; NFA is often more compact
DFA vs NFA Comparison Table
| Feature | DFA | NFA |
| Full Form | Deterministic Finite Automata | Non-Deterministic Finite Automata |
| Transition Rule | Exactly one state per input symbol | Zero, one, or multiple states per input symbol |
| Epsilon Transitions | Not allowed | Allowed |
| Ease of Construction | Often harder for complex languages | Often easier for complex languages |
| Execution | Follows one single path | Can explore multiple paths at once (conceptually) |
| Speed of Execution | Faster, since there is no branching | Can be slower without conversion to DFA |
| Memory Usage | Can need more states | Can need fewer states |
| Implementation in Code | Straightforward, like a lookup table | Requires backtracking or subset construction |
| Power | Equivalent to NFA in language recognition | Equivalent to DFA in language recognition |
Transition Rules
In a DFA, the transition function always returns one and only one state. In an NFA, the transition function returns a set of states, which can be empty, contain one state, or contain several.
Number of Next States
DFA: always exactly 1. NFA: 0 or more, with no upper limit other than the total number of states.
Epsilon Transitions
DFA strictly forbids transitions that do not consume an input symbol. NFA allows them, letting the machine “jump” to another state for free, which is especially useful when combining smaller automata into one larger one.
State Complexity
A DFA built to recognize the same language as an NFA can require exponentially more states in the worst case, because each DFA state may represent a combination of NFA states (this is the basis of the subset construction algorithm covered later).
Memory Usage
Because of state complexity, DFAs can sometimes demand more memory to store all their states and transitions, even though each individual computation step is simpler.
Execution Behavior
A DFA processes a string in a single, linear pass. An NFA conceptually checks all valid paths and accepts the string if any single path reaches an accepting state.
Implementation Difficulty
DFAs are simple to implement as a transition table or a switch statement. NFAs typically need either a conversion to DFA first, or a simulation technique that tracks multiple “current states” at once.
Performance
DFA execution time depends only on the length of the input string. NFA execution, if simulated directly without conversion, can take longer because of the branching paths, although in practice most systems convert NFA to DFA before runtime for this reason.
Applications
DFA is the default choice when speed and predictability matter, such as live text scanning. NFA is the default choice when design simplicity matters more than raw execution speed, such as drafting a regular expression before it gets compiled into a DFA.
Visual Comparison of DFA and NFA
DFA Diagram
A DFA diagram always has a single arrow leaving each state for each symbol in the alphabet. If you trace any state with your finger and follow one input symbol, there is never more than one arrow to follow.
NFA Diagram
An NFA diagram can show two or more arrows leaving the same state with the same label, or dashed arrows labeled with ε representing free transitions between states.
Side-by-Side Analysis
If you place both diagrams next to each other for a language like “strings ending in 1,” the NFA diagram usually looks lighter and has fewer states, while the DFA diagram looks busier but never has any ambiguity about which arrow to follow next.
Real-Life Analogy to Understand DFA and NFA
GPS Route Example
Imagine asking for directions to a coffee shop. A DFA is like a GPS that gives you exactly one route and one set of turns, with no alternatives. You follow it step by step, and there is never a moment of choice.
An NFA is like a GPS that shows you three possible routes at once: one through downtown, one along the highway, and one through side streets. You don’t know in advance which one will get you there fastest, but as long as at least one of these routes successfully reaches the coffee shop, you call the trip a success.
Maze Navigation Example
A DFA solving a maze can only move in one predetermined direction at every junction, based on a strict rulebook. An NFA solving the same maze is allowed to try multiple paths at every junction simultaneously (in theory), and the maze is considered “solved” if even one of those paths reaches the exit.
Why DFA and NFA Are Equivalent
This is the part that confuses most students: if NFA seems more flexible, doesn’t that make it more powerful? The answer is no.
Acceptance Power
DFA and NFA recognize exactly the same class of languages: regular languages. Anything an NFA can accept, some DFA can also accept, and vice versa. The flexibility of NFA is a convenience for design, not an increase in computational power.
Regular Languages
A regular language is any language that can be described by a regular expression or recognized by a finite automaton. Both DFA and NFA are tools for recognizing this same set of languages, just with different internal mechanics.
Formal Proof Concept
The equivalence is proven constructively: for any NFA, you can build an equivalent DFA using the subset construction algorithm (covered in the next section). Since a DFA can always be built to match any NFA’s behavior exactly, the two models are proven to have identical recognition power.
How to Convert NFA to DFA
What Is Subset Construction?
Subset construction is the standard algorithm for converting an NFA into an equivalent DFA. The core idea: each state in the new DFA represents a set of states the NFA could possibly be in at that point.
Conversion Algorithm
- Start with the epsilon closure of the NFA’s start state as the DFA’s start state
- For each DFA state (a set of NFA states) and each input symbol, compute the set of NFA states reachable
- Add any newly discovered sets as new DFA states
- Repeat until no new sets appear
- Mark any DFA state as accepting if it contains at least one NFA accepting state
Step-by-Step Example
Take the earlier NFA: states q0 and q1, where on input “1” from q0 the machine can go to either q0 or q1, and on input “0” it stays at q0. q1 is the only accepting state.
Initial State
Begin with {q0} as the DFA start state, since that’s where the NFA starts and there are no epsilon transitions to expand it.
State Subsets
From {q0}, on input 0, the NFA stays at q0, so the DFA transitions to {q0}.
From {q0}, on input 1, the NFA can go to q0 or q1, so the DFA transitions to a new combined state {q0, q1}.
From {q0, q1}, on input 0, only q0 has a defined transition on 0 (back to q0), so the DFA goes to {q0}.
From {q0, q1}, on input 1, both q0 and q1 lead back to {q0, q1} (since q1 in this example has no outgoing transitions, only q0’s branching applies, keeping the set the same).
Transition Mapping
| DFA State | Input 0 | Input 1 |
| {q0} | {q0} | {q0, q1} |
| {q0, q1} | {q0} | {q0, q1} |
Final DFA
The resulting DFA has two states: {q0} (start, non-accepting) and {q0, q1} (accepting, since it contains q1). This DFA behaves identically to the original NFA for every possible input string, but now every transition is single and deterministic.
Advantages and Disadvantages of DFA
Advantages
- Predictable, single-path execution with no ambiguity
- Faster runtime since there is no need to track multiple states
- Simple to implement as a transition table in any programming language
- Well suited for hardware-level implementation
Disadvantages
- Can require significantly more states than an equivalent NFA
- Harder to design by hand for complex languages
- Modifying a DFA’s behavior often means redesigning large parts of the state diagram
Advantages and Disadvantages of NFA
Advantages
- Often much easier and faster to design, especially for complex patterns
- Naturally maps to regular expression syntax
- Combining smaller automata together is simpler thanks to epsilon transitions
- Can require fewer states than an equivalent DFA
Disadvantages
- Cannot be directly executed without simulation or conversion
- Conversion to DFA can cause exponential state growth in the worst case
- Less intuitive to implement directly as working code
Applications of DFA and NFA
Compiler Design
Compilers use finite automata in their lexical analysis phase to break source code into meaningful tokens like keywords, identifiers, and operators.
Lexical Analysis
A lexical analyzer (or “lexer”) reads a program character by character and groups characters into tokens. DFAs are preferred here because the predictable, single-path execution keeps scanning fast even on large files.
Pattern Matching
String searching algorithms, including those used in search engines and text editors, rely on automata-based logic to scan for matches efficiently.
Regular Expressions
Every regular expression can be converted into an NFA first, then into a DFA, which is exactly how most regex engines work internally, even if the engine hides this process from the developer.
Text Processing
Tools like grep, spell checkers, and syntax highlighters in code editors all depend on finite automata to identify patterns in text quickly.
Common Misconceptions About DFA and NFA
Is NFA More Powerful?
No. This is the single most common misconception. NFA and DFA recognize exactly the same set of languages, regular languages. NFA is more convenient for design, not more powerful in what it can compute.
Does NFA Run Multiple Machines?
Not literally. An NFA does not physically run several machines in parallel. It is a mathematical model where multiple paths are possible, and the string is accepted if at least one path works. In practice, simulating an NFA on a computer tracks a set of “currently possible states,” not separate running machines.
Is DFA Always Better?
Not necessarily. DFA wins on raw execution speed and predictability, but NFA wins on design simplicity and can be more compact in terms of state count. The right choice depends on whether you’re optimizing for runtime performance or ease of construction.
DFA vs NFA for Exams and Interviews
Important Viva Questions
- What is the formal definition of a DFA and an NFA?
- Why does an NFA’s transition function return a set of states instead of a single state?
- What is an epsilon transition, and why is it not allowed in a DFA?
- Explain the subset construction algorithm in your own words.
- Why are DFA and NFA considered computationally equivalent?
GATE Exam Notes
- Memorize the formal 5-tuple definitions of both DFA and NFA
- Practice subset construction on at least three different NFAs by hand
- Remember: NFA with n states converts to a DFA with at most 2^n states in the worst case
- Be ready to trace string acceptance step by step for both DFA and NFA
- Know that both models recognize exactly regular languages, nothing more, nothing less
Quick Revision Table
| Concept | DFA | NFA |
| Transitions per symbol | Exactly 1 | 0 or more |
| Epsilon transitions | No | Yes |
| Power | Regular languages | Regular languages (same) |
| Worst-case states after conversion | N/A | Up to 2^n as a DFA |
| Best for | Execution speed | Design simplicity |
Frequently Asked Questions
1. What is the main difference between DFA and NFA?
A DFA allows exactly one transition per state for each input symbol, while an NFA allows multiple transitions, zero transitions, or epsilon transitions for the same state and symbol.
2. Which is more powerful?
Neither. DFA and NFA are equally powerful in terms of the languages they can recognize, both are limited to regular languages.
3. Can every NFA become a DFA?
Yes. Every NFA can be converted into an equivalent DFA using the subset construction algorithm, although the resulting DFA may have significantly more states.
4. Does DFA allow epsilon transitions?
No. Epsilon transitions are strictly forbidden in a DFA. Every transition must consume exactly one input symbol.
5. Why is DFA used in lexical analysis?
Because DFA execution is fast and predictable, with each input character processed in one deterministic step, which keeps compiler scanning efficient even for large source files.
6. What are regular languages?
Regular languages are the set of languages that can be described using regular expressions, and they are exactly the languages that both DFA and NFA are capable of recognizing.
Key Takeaways
Quick Summary Table
| Aspect | DFA | NFA |
| Determinism | Fully deterministic | Non-deterministic |
| Design difficulty | Often harder | Often easier |
| Execution speed | Faster | Slower without conversion |
| Epsilon transitions | Not allowed | Allowed |
| Recognized languages | Regular languages | Regular languages (identical) |
conclusion
DFA and NFA are two ways to describe the same thing. DFA is good because it is fast and you can tell what it will do.. It is hard to make a DFA. NFA is easier to make. It is slow. You have to change an NFA to a DFA before it can run fast. If you want to make a compiler or a regex engine you need to know about DFA and NFA. How they are connected.









